AVL/RBTREE 实际比较
网上对 AVL被批的很惨,认为性能不如 rbtree,这里给 AVL 树平反昭雪。最近优化了一下我之前的 AVL 树,总体跑的和 linux 的 rbtree 一样快了:
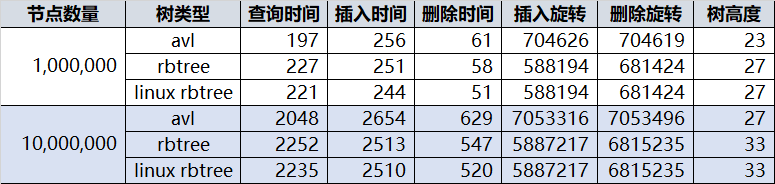
他们都比 std::map 快很多(即便使用动态内存分配,为每个新插入节点临时分配个新内存)。
项目代码在:skywind3000/avlmini 其他 AVL/RBTREE 评测也有类似的结论,见:STL AVL Map
谣言1:RBTREE的平均统计性能比 AVL 好
统计下来一千万个节点插入 AVL 共旋转 7053316 次(先左后右算两次),RBTREE共旋转 5887217 次,RBTREE看起来少是吧?应该很快?但是别忘了 RBTREE 再平衡的操作除了旋转外还有再着色,每次再平衡噼里啪啦的改一片颜色,父亲节点,叔叔,祖父,兄弟节点都要访问一圈,这些都是代价,再者平均树高比 AVL 高也成为各项操作的成本。
谣言2:RBTREE 一般情况只比 AVL 高一两层,这个代价忽略不计
纯粹谣言,随便随机一下,一百万个节点的 RBTREE 树高27,和一千万个节点的 AVL树相同,而一千万个节点的 RBTREE 树高 33,比 AVL 多了 6 层,这还不是最坏情况,最坏情况 AVL 只有 1.440 * log(n + 2) - 0.328, 而 RBTREE 是 2 * log(n + 1),也就是说同样100万个节点,AVL最坏情况是 28 层,rbtree 最坏可以到 39 层。
谣言3:AVL树删除节点是需要回溯到根节点
我以前也是这么写 AVL 树的,后来发现根据 AVL 的定义,可以做出两个推论,再平衡向上回溯时:
插入更新时:如当前节点的高度没有改变,则上面所有父节点的高度和平衡也不会改变。 删除更新时:如当前节点的高度没有改变且平衡值在 [-1, 1] 区间,则所有父节点的高度和平衡都不会改变。
根据这两个推论,AVL的插入和删除大部分时候只需要向上回溯一两个节点即可,范围十分紧凑。
谣言4:虽然二者插入一万个节点总时间类似,但是rbtree树更平均,avl有时很快,有时慢很多,rbtree 只需要旋转两次重新染色就行了,比 avl 平均
完全说反了,avl是公认的比rbtree平均的数据结构,插入时间更为平均,rbtree才是不均衡,有时候直接插入就返回了(上面是黑色节点),有时候插入要染色几个节点但不旋转,有时候还要两次旋转再染色然后递归到父节点。该说法最大的问题是以为 rbtree 插入节点最坏情况是两次旋转加染色,可是忘记了一条,需要向父节点递归,比如:当前节点需要旋转两次重染色,然后递归到父节点再旋转两次重染色,再递归到父节点的父节点,直到满足 rbtree 的5个条件。这种说法直接把递归给搞忘记了,翻翻看 linux 的 rbtree 代码看看,再平衡时那一堆的 while 循环是在干嘛?不就是向父节点递归么?avl和rbtree 插入和删除的最坏情况都需要递归到根节点,都可能需要一路旋转上去,否则你设想下,假设你一直再树的最左边插入1000个新节点,每次都想再局部转两次染染色,而不去调整整棵树,不动根节点,可能么?只是说整个过程avl更加平均而已。
比较结论
AVL / RBTREE 真的差不多,AVL被早期各种乱七八糟的实现和数学上的“统计”给害了,别盯着 linux 用了 rbtree 就觉得 rbtree 一定好过 avl了,solaris 里面大范围的使用 avltree ,完全没有 rbtree 的痕迹那。
补充测试
更新:有人比较疑惑 std::map 那么容易被超越么?无图无真相,给一下我测试的编译器和标准库版本吧,否则疑惑我在和 vc6 的 STL 做比较呢。
主要开发环境:mingw gcc 5.2.0
linux rbtree with 10000000 nodes:
insert time: 4451ms, height=32
search time: 2037ms error=0
delete time: 548ms
total: 7036ms
avlmini with 10000000 nodes:
insert time: 4563ms, height=27
search time: 2018ms error=0
delete time: 598ms
total: 7179ms
std::map with 10000000 nodes:
insert time: 4281ms
search time: 4124ms error=0
delete time: 767ms
total: 9172ms
linux rbtree with 1000000 nodes:
insert time: 355ms, height=26
search time: 171ms error=0
delete time: 46ms
total: 572ms
avlmini with 1000000 nodes:
insert time: 438ms, height=24
search time: 141ms error=0
delete time: 47ms
total: 626ms
std::map with 1000000 nodes:
insert time: 345ms
search time: 360ms error=0
delete time: 62ms
total: 767ms
又测试了一下 vs2017,结论类似:
linux rbtree with 10000000 nodes:
insert time: 4201ms, height=32
search time: 3411ms error=0
delete time: 567ms
total: 8179ms
avlmini with 10000000 nodes:
insert time: 4250ms, height=27
search time: 3233ms error=0
delete time: 658ms
total: 8141ms
std::map with 10000000 nodes:
insert time: 4658ms
search time: 4275ms error=0
delete time: 815ms
total: 9748ms
linux rbtree with 1000000 nodes:
insert time: 330ms, height=26
search time: 316ms error=0
delete time: 62ms
total: 708ms
avlmini with 1000000 nodes:
insert time: 409ms, height=24
search time: 266ms error=0
delete time: 53ms
total: 728ms
std::map with 1000000 nodes:
insert time: 426ms
search time: 375ms error=0
delete time: 78ms
total: 879ms
注意,avlmini 和 linux rbtree 都是使用结构体内嵌的形式,这样和 std::map 这种需要 overhead 的容器比较起来 std::map 太吃亏了,所以我测试时,每次插入 avlmini 和 linux rbtree 之前都会模拟 std::map 为每对新的 (key, value) 分配一个结构体(包含node信息和 key, value),再插入,这样加入了内存分配的开销,才和 std::map 进行比较。
参考:别人做的更多树和哈希表的评测 rcarbone/kudb