分类 编程技术 中的文章
[业余土制] Build工具 EasyMake
[自制开源] 轻量级图形库 PixelLib
- 图像:64种不同的像素格式,色彩空间变换,多种图形图像变换。
- 质量:支持3种级别抗锯齿效果,高质量几何图形绘制。
- 实现:轻量级纯软件实现,100% C代码(仅700KB代码)。
- 优化:SSE2/MMX优化 地址:https://github.com/skywind3000/pixellib
1. 图像变换:
![]()
支持仿射变换和透视变换,提供大量图像变换操作接口。
2. 抗锯齿:
![]()
所有图形绘制支持3级不同程度的抗锯齿效果。
3. 图像绘制:
![]()
图像任意拉伸,旋转,3D旋转,并且同时进行色彩空间变换。全部采用浮点数坐标,图像移动更为平滑。
4. 几何作图:
![]()
全面的抗锯齿几何作图效果。
5. 图像扭曲:
![]()
在源图像上布置若干关键点,然后改变这些关键点在屏幕上的对于位置即可实现图像扭曲。
**使用 Pixellib 来渲染 iOS 风格的图标 **
![]()
[业余土制] 实时汇编编译器
实时动态在内存中编译汇编代码,并返回函数调用指针,可用于JIT系统的后端:
项目地址:https://github.com/skywind3000/asmpure 例子:
const char *AlphaBlendAsm =
"PROC C1:DWORD, C2:DWORD, A:DWORD\n"
" movd mm0, A\n"
" punpcklwd mm0, mm0\n"
" punpckldq mm0, mm0\n"
" pcmpeqb mm7, mm7\n"
" psubw mm7, mm0\n"
" \n"
" punpcklbw mm1, C1\n"
" psrlw mm1, 8\n"
" punpcklbw mm2, C2\n"
" psrlw mm2, 8\n"
" \n"
" pmullw mm1, mm7\n"
" pmullw mm2, mm0\n"
" paddw mm1, mm2\n"
" \n"
" psrlw mm1, 8\n"
" packuswb mm1, mm1\n"
" movd eax, mm1\n"
" emms\n"
" ret\n"
"ENDP\n";
void testAlphaBlend(void)
{
CAssembler *casm;
int c;
int (*AlphaBlendPtr)(int, int, int);
// create assembler
casm = casm_create();
// append assembly source
casm_source(casm, AlphaBlendAsm);
AlphaBlendPtr = (int (*)(int, int, int))casm_callable(casm, NULL);
if (AlphaBlendPtr == NULL) {
printf("error: %s\n", casm->error);
casm_release(casm);
return;
}
printf("==================== Alpha Blend ====================\n");
casm_dumpinst(casm, stdout);
printf("\nExecute code (y/n)?\n\n");
do
{
c = getch();
}
while(c != 'y' && c != 'n');
if(c == 'y')
{
int x = AlphaBlendPtr(0x00FF00FF, 0xFF00FF00, 128);
printf("output: %.8X\n\n", x);
}
free(AlphaBlendPtr);
casm_release(casm);
}
**output: 7f7f7f7f **
……[游戏演示] ActionScript 鼠标手势识别
PowerPC 汇编入门与优化
PowerPC于1991年IBM/MOTO/APPLE研制,大量应用于服务器(AIX / AS400系列及苹果系列服务器),家用游戏机(PS3, Wii, XBOX, GameCube),以及嵌入式(仅次于Arm/x86排第三)。PowerPC核心在于开放系统软件标准,其应用范围仅次于x86,是除去x86外最值得开发者了解的体系。
不需要写出非常高效的代码,但要了解基本效率原则;不需要大规模开发PPC程序,但需要时能写几段、调试时能看懂哪里错了。本文将从对比x86入手,引入RISC及PowerPC体系概念,向读者介绍该体系指令集,常用优化方法和交叉编译环境及模拟器的搭建等内容。
下载阅读:powerpc_figure_0408
PowerPC Figure – PPC入门与优化
By Skywind(2007)
http://www.skywind.me/blog/
背景介绍
PowerPC于1991年IBM/MOTO/APPLE研制,大量应用于服务器(AIX / AS400系列及苹果系列服务器),家用游戏机(PS3, Wii, XBOX, GameCube),以及嵌入式(仅次于Arm/x86排第三)。PowerPC核心在于开放系统软件标准,其应用范围仅次于x86,是除去x86外最值得开发者了解的体系。
不需要写出非常高效的代码,但要了解基本效率原则;不需要大规模开发PPC程序,但需要时能写几段、调试时能看懂哪里错了。本文将从对比x86入手,引入RISC及PowerPC体系概念,向读者介绍该体系指令集,常用优化方法和交叉编译环境及模拟器的搭建等内容。
……SlabPlus 内存分配算法
原理叙述:
我也来介绍一种内存管理方面的优化算法:怎样才能根除内存碎片?有且只有如下办法:1. 只分配不释放,2. 只分配固定大小内存,3. 不分配内存,虽然,仍不妨碍我们再一次回顾各种常用的分配策略,以发掘一些新的思路:
前提:下面提及的分配技巧并不能说是“最快的”,也不能说是“最小碎片的”,但是可以保证,不管系统运行多长时间,不管分配多大内存,碎片比例趋于恒定,同时分配时间为常数(unit interval):
最后将讨论一些更进一步的优化技巧(如果愿意大量增加代码行数的话),看看在分配内存方面,哪些我们值得努力,哪些不值得我们努力。
现代的内存分配算法,需要顾及以下几个特性:
1) 缓存命中:现今的计算机体系,优秀的缓存策略对一个系统而言异常重要,一些写的不太注意的分配器,容易忽略该特性,前分配一块内存,后分配一块内存,大大增加了缓存的失效。
2) 总线平衡:大部分缓存管理都是提供 2^n字节大小的内存机制,并且所分配地址也是以 2^n字节进行对齐,比如我们有一个 packfile对象有400多个字节,将使用 512字节的缓存分配器,并且按照 512字节进行对齐,但是问题在于,大部分时候我们都在访问该对象的头30个字节,因此在(0-30) mod 512的地方,也就是在以512字节为分割的缓存线周围集中了大量的压力,在现今的大部分普通的缓存芯片上将出现总线失衡bus-overbalance。
3) 页面归还:何时向系统请求页面,何时归还系统页面,很多分配器只向系统不停的申请页面,却并不考虑提供保证能够正常不断的归还系统页面的机制。
4) 多核优化:尽管多核技术现在才逐渐在PC上推广,但我们的服务器很早就已经开始使用双核或者四核的架构,分配器如何尽量避免在不同核间产生的等待,是分配器效率优化的一个前提。
以下几点内容有助于优化我们的分配器:
……影子跟随算法(2007年老文一篇)
算法简述
动作类游戏如何在高延迟下实现同步?不同的客户端网络情况,如何实现延迟补偿?十年前开始关注该问题,转眼十年已过,看到大家还在问这类问题,旧文一篇,略作补充(关于游戏同步相关问题还可以见我写于2005年的另外两篇文章,帧锁定算法 和 网游同步法则):
影子跟随算法由普通DR(dead reckoning)算法发展而来,我将其称为“影子跟随”意再表示算法同步策略的主要思想:
1. 屏幕上现实的实体(entity)只是不停的追逐它的“影子”(shadow)。
2. 服务器向各客户端发送各个影子的状态改变(坐标,方向,速度,时间)。
3. 各个客户端收到以后按照当前重新插值修正影子状态。
4. 影子状态是跳变的,但实体追赶影子是连续的,故整个过程是平滑的。
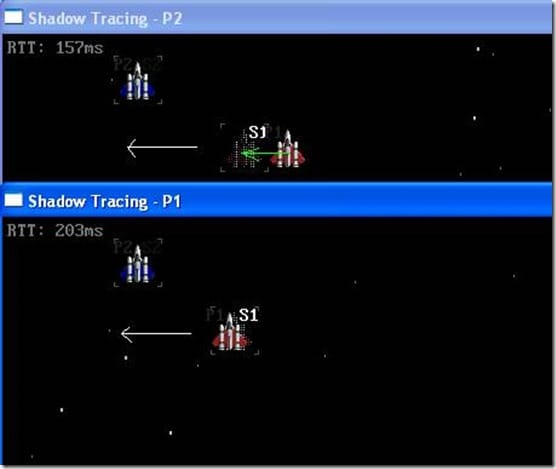
图 1 算法演示
……超越 STL-map/hash_map性能的DICT
最近用纯C作了一个dict,根据试验,比 stl的 map快 2.3-2.5倍,比 hash_map快 1.3倍,主要用到的优化策略如下:
1. skiplist:
传统hash-bucket中,使用链表靠 next, 指针记录同一个 bucket中的各个节点,查找时候 需要一个一个的搜索,而改进以后的 bucket节点,使用 next, next4, next8三级指针,分别指向后一个节点,后四个节点,后八个节点,如此保证链表有序的情况下,如果要搜索,就直接考虑 next8的值和当前值大小,如果小于当前值,直接跳过八个节点,如果大于那再一次判断 next4与next。如此有序链表的遍历速度提高了 8倍。
2. 双hash:
使用两次hash,开辟一个长度为 64的 LRU数组,记录最近访问过的节点,使用 hash2来定位 LRU数组的位置,当搜索发生时,首先根据 hash2在 LRU数组中查找是否最近访问过该节点,如果访问过就直接返回,如果没有访问过则继续用 hash1在 bucket中查找,如果查找到的话,就按照 hash2的值覆盖一下 LRU中该位置的数据。 再加上一些内存管理方面的优化,以及一些编码方式的改进,对 key/value分别取 string或 int,四种情况下,平均比 stl的 map快 2.3-2.5倍,比 hash_map快 1.3倍。
……ASCII Art Algorithm
因为希望将图片转换成字符以后可以方便的帖到论坛或者BBS上,所以画时间写了这个算法。
现有很多算法都是将一个点匹配成一个字符,这样转换工作只是简单的将点亮度查表后换成ASCII字符而已,但是其实这样做的效果并不十分好,首先80x25的字符屏幕就只能表示80x25个点,无法充分发挥单个字符的字形特点,而且图片很多精度和细节都丢失了。比如下面这个连接:
{kind=link}
所以我的算法主要是匹配周围一部分点到ASCII字符,这样斜线能够顺利匹配成“/”,其他形状的东西也能够顺利按照字形特点进行匹配,因此同样80x25个点,但是后者所能够表达的像素点更多,细节度更加丰富:

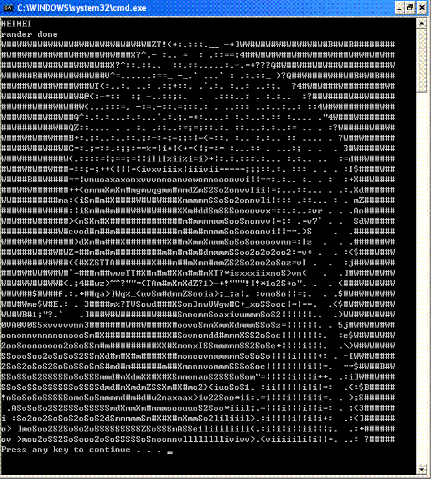
上面的效果是作了误差扩散的,其实转换成ASCII字符时不做也可以,只是说希望转换前的局部/整体亮度等于转换后亮度,能量守恒一些而已。
其实如果用同 一种颜色的64个常见字符表达精度和细节度很高,对比度不高的图片还是比较困难的,可以进一步优化的方法也有几种,其一是对照片作拉普拉斯变换,将噪声过 滤掉再取出轮廓,这样转换出来的就是仅仅包含轮廓的对比度很高的图片了。
或者将图片频谱中能量不高的,比较弱的频率去掉,留下能量高的频率,这样图片看起 来更干净一些,只是后面这两种方法就无法保证实时渲染了。
……