行为树的疑问
……关于行为树的实现,我在网上看到几个实现版本都对节点规划了running状态,表示节点的动作未执行完毕,每次执行时从上次未执行完毕的节点开始执行而跳过之前已经执行完毕的节点。
问题在于,处于同一selector节点下的子节点,位置越靠前的节点优先级是越高的,如果因为running恢复机制而跳过了已经执行完毕的节点,岂不是无法实现“打断”现有逻辑的需求?
我想问,节点running状态的引入是为了解决什么问题?为什么不每次都top-down执行所有节点?
写自己的代码,让别人猜去吧!
……关于行为树的实现,我在网上看到几个实现版本都对节点规划了running状态,表示节点的动作未执行完毕,每次执行时从上次未执行完毕的节点开始执行而跳过之前已经执行完毕的节点。
问题在于,处于同一selector节点下的子节点,位置越靠前的节点优先级是越高的,如果因为running恢复机制而跳过了已经执行完毕的节点,岂不是无法实现“打断”现有逻辑的需求?
我想问,节点running状态的引入是为了解决什么问题?为什么不每次都top-down执行所有节点?
知乎上有人问:“贴吧都是十五六岁就用引擎写游戏的天才,大家怎么看?”,感觉现在做游戏真实一件幸福的事情呀,不尽想起当年开发游戏的各种艰辛。
现在做游戏很简单,大把代码给你参考,大把框架给你使用,Windows帮你作完了大部分事情。我们那个年纪写游戏时,家里还没有Internet,什么资料都查不到,什么开源引擎都没有,95年左右你要写一个游戏,你起码面临:
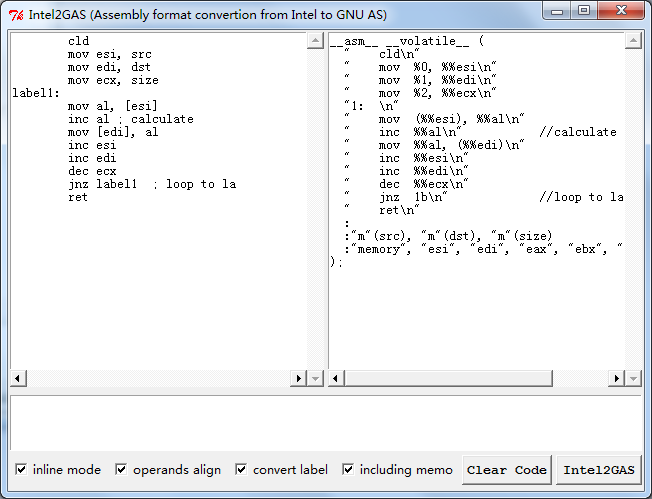
常用 MSVC写内嵌汇编需要兼容 GCC是一件头疼的事情,不是说你不会写 GCC的 AT&T风格汇编,而是说同一份代码写两遍,还要调试两遍,是一件头疼的事情,特别是汇编写了上百行的时候。于是五年前写过一个小工具,可以方便的进行转换,能把 MSVC/MASM的汇编转成纯 AT&T风格汇编,或者 GCC Inline风格汇编,自动识别寄存器和变量,还有跳转地址,并且自动导出。今天把他放上来,或许有用到的人吧。
BehaviorTree:国内很多正式商用项目确实用了,不管RTS,还是RPG,而且用的还行,毕竟写AI一大半时间在调试上,有图形化的界面,调试起来更方便点,有的项目策划可以直接来写AI。值得花时间封装的东西,你做出一套来,以后其他项目都可以用,但是两个人一个多月的时间是最起码的。
一个人写一个GUI编辑器,另一个人写 BehaviorTree的运行时,用你们熟悉的语言来写。包括若干基类,运行跟踪,状态单步,以及可以脱离游戏环境的调试方式。如果找到称手的AI框架,拿过来, 比如你可以评估下 U3D的 BehaviorTree的库和编辑器是否可以,能否集成到你的项目?我自己没有用过,我们用自己之前的一个实现。
NaviMesh:大部分情况最好不用,现在国内大部分游戏都是显示3D,但是内部数据还是2D的,比如地图,还是用的格子,在这种情况下,引入NaviMesh会逼迫你客户端使用全3D数据结构,并且逼迫你服务端从2D计算升级到3D计算,主要是 NaviMesh实现起来起码也要一个多月,然后要调试很久。
……程序员也有三六九等:
初等程序员靠知识来挣钱,会别人会的东西,喜欢折腾架构和框架,以掌握更多新潮东西而沾沾自喜,以模仿各种奇技淫巧重新实现一遍而四处炫耀,常见台词:“为啥还在用png存图片?为啥不用webp这种高压缩比的格式?”,“我们使用 Erlang的高并发特性来实现同时支持5万人的效果”,“我们使用RTMFP来降低流量成本,又使用H265来给用户提供更高品质的视频画质”,这些人能够迅速的学会各种项目需要的架构套件,以自己的生产力来挣钱。
高等程序员靠智慧挣钱,会别人不会的东西,上能抉择技术方向,下能解决性能瓶颈;讨论方案时,腾讯怎么做的,阿里怎么做的,我们该怎么做,如数家珍;写完代码后,初读让人赏心悦目,再读让人恍然大悟,三读让人心悦诚服。常见台词:“webp压缩比不高,我改了一版新webp,用H265帧内预测来保存RGB,用lzma2来保存alpha比webp好多了”,“erlang大家不熟悉,我做了一个库,让大家可以象写erl ang一样来写C++,照顾大家开发习惯,又可以象erlang一样写多线程”。“Micheal Abrash这几行代码还有很大优化空间,其实性能还可以更好!”她们都是以解决别人不能解决的问题来挣钱。
上等程序员靠创新来挣钱,能促进行业的发展,在这个充满咨询的年代,学习大家都掌握的东西只是一个基本过程,没什么值得称道的,当你baidu上找不到方案,google里没有参考,国内外没有任何人能给你启示的时候,任然能够充满创造的分析问题,抽象问题,并解决问题。找到别人完全没有走过的路,创造前人从来没有创造过的东西,这是他们的价值所在。他们的常见台词是:“别烦我!”,“忙着呢!”,“谷歌搜呀,这都问我? ”,上等程序员是国宝,他们的时间不应该浪费在无意义的事情上。
即便做到上面几点,在神级程序员眼里,也只不过如此罢了。真正的神级程序员,不靠知识和智慧挣钱,更不靠创新来挣钱,而是靠意志来挣钱,十八般语言门门精通,上能架构操作系统,下可开发嵌入芯片;成功项目无数份,胸中代码千万行!不果这些也只是基本功而已,牛逼的神级程序员,左手抱四十八斤人体工学键盘,右手提二百斤纯铁鼠标,竞争对手哪怕有千军万马,也近不得他办公桌前半步!三十六小时连续编码依旧气定神闲,体力耐力无 人能及。上市公司首席科学家,创新项目的领导者,在他们看来,也只是尘土而已,不出三回合,毕斩其首级于电脑前。他们常见的台词是:“杀!”,“弄死你!”,高手们总是睥睨天下而又冷言少语。
……移动设备多用手势进行输入,用户通过手指在屏幕上画出一个特定符号,计算机识别出来后给予响应的反应,要比让用户点击繁琐的按钮为直接和有趣,而如果为每种手势编写一段识别代码的话是件得不偿失的事情。如何设计一种通用的手势识别算法来完成上面的事情呢? 我们可以模仿笔记识别方法,实现一个简单的笔画识别模块,流程如下:
1. 手指按下时开始记录轨迹点,每划过一个新的点就记录到手势描述数组guesture中,直到手指离开屏幕。 2. 将gesture数组里每个点的x,y坐标最大值与最小值求出中上下左右的边缘,求出该手势路径点的覆盖面积。 3. 手势坐标归一化:以手势中心点为原点,将gesture里顶点归一化到 -1<=x<=1, -1<=y<=1空间中。 4. 数组长度归一化:将手势路径按照长度均匀划分成32段,用共32个新顶点替换guestue里的老顶点。
1. 手势点乘:
g1 * g2 = g1.x1*g2.x1 + g1.y1*g2.y1 + … + g1.x32*g2.x32 + g1.y32*g2.y32
2. 手势相似:
相似度(g1, g2) = g1 * g2 / sqrt(g1 * g1 + g2 * g2)
由此我们可以根据两个手势的相似度算成一个分数score。用户输入了一个手势g,我们回合手势样本中的所有样本g1-gn打一次相似度分数,然后求出相似度最大的那个样本gm并且该分数大于某个特定阀值(比如0.8),即可以判断用户输入g相似于手势样本 gm !
……如果你正在使用 Flash,那么实现下面一个字体效果是一件十分简单的事情:
textfield.filters = [ new GlowFilter(0, 1, 2, 2, 10) ];
这样就可以了,接着把字体设置成宋体12号,颜色是0xffff99,就成了。

如果要实现上面类似QQ面板的发光效果,也只需要一行:
textfield.filters = [ new GlowFilter(0xffffffff, 1, 6, 6, 0.9) ];
看起来这个 GlowFilter是无所不能呀,那么如果你在使用C++的话,如何用C++来实现一个Glow效果呢?
而且如果你正在使用3D引擎的话,如何用GPU来实现上面的效果呢?详细见下文:
TO BE CONTINUE….
……KCP是一个快速可靠协议,能以比 TCP浪费10%-20%的带宽的代价,换取平均延迟降低 30%-40%,且最大延迟降低三倍的传输效果。纯算法实现,并不负责底层协议(如UDP)的收发,需要使用者自己定义下层数据包的发送方式,以 callback的方式提供给 KCP。 连时钟都需要外部传递进来,内部不会有任何一次系统调用。
整个协议只有 ikcp.h, ikcp.c两个源文件,可以方便的集成到用户自己的协议栈中。也许你实现了一个P2P,或者某个基于 UDP的协议,而缺乏一套完善的ARQ可靠协议实现,那么简单的拷贝这两个文件到现有项目中,稍微编写两行代码,即可使用。
TCP是为流量设计的(每秒内可以传输多少KB的数据),讲究的是充分利用带宽。而 KCP是为流速设计的(单个数据包从一端发送到一端需要多少时间),以10%-20%带宽浪费的代价换取了比 TCP快30%-40%的传输速度。TCP信道是一条流速很慢,但每秒流量很大的大运河,而KCP是水流湍急的小激流。KCP有正常模式和快速模式两种,通过以下策略达到提高流速的结果:
RTO翻倍vs不翻倍:
TCP超时计算是RTOx2,这样连续丢三次包就变成RTOx8了,十分恐怖,而KCP启动快速模式后不x2,只是x1.5(实验证明1.5这个值相对比较好),提高了传输速度。
选择性重传 vs 全部重传:
TCP丢包时会全部重传从丢的那个包开始以后的数据,KCP是选择性重传,只重传真正丢失的数据包。
快速重传:
发送端发送了1,2,3,4,5几个包,然后收到远端的ACK: 1, 3, 4, 5,当收到ACK3时,KCP知道2被跳过1次,收到ACK4时,知道2被跳过了2次,此时可以认为2号丢失,不用等超时,直接重传2号包,大大改善了丢包时的传输速度。
延迟ACK vs 非延迟ACK:
TCP为了充分利用带宽,延迟发送ACK(NODELAY都没用),这样超时计算会算出较大 RTT时间,延长了丢包时的判断过程。KCP的ACK是否延迟发送可以调节。
UNA vs ACK+UNA:
ARQ模型响应有两种,UNA(此编号前所有包已收到,如TCP)和ACK(该编号包已收到),光用UNA将导致全部重传,光用ACK则丢失成本太高,以往协议都是二选其一,而 KCP协议中,除去单独的 ACK包外,所有包都有UNA信息。
非退让流控:
KCP正常模式同TCP一样使用公平退让法则,即发送窗口大小由:发送缓存大小、接收端剩余接收缓存大小、丢包退让及慢启动这四要素决定。但传送及时性要求很高的小数据时,可选择通过配置跳过后两步,仅用前两项来控制发送频率。以牺牲部分公平性及带宽利用率之代价,换取了开着BT都能流畅传输的效果。
国庆没事,想看看最少多少行可以写一个人机对战棋类游戏,于是有了这个Python版五子棋人机对战,仅仅几百行。

再命令行输入横竖坐标就可以和机器人对弈了,多种难度选择。
https://github.com/skywind3000/gobang
下面是代码(点击More展开)
……中心思想就是两个字“忠义”,哪怕这个制度已经腐朽了,哪怕让自己和兄弟被害死,但仍要忠于皇上,这种“大忠大义”被导演讴歌的无处不在,大结还被局命名为“忠义参天”。
导演真是煞费苦心呀,为了表现宋江的英雄气概,强行加了很多原著上没有的台词,什么“犯我中华者虽远必诛”来突出他的气概,很多吴用说的经典台词也挪给宋江来突出他的智谋。让宋江这个机会主义者和投降主义者摇身一变成为一个忠义英雄,打着替天行道大旗骗民心,跟皇帝搞统一战线维稳,打农民起义军。
鲁迅说过:“一部《水浒》,说得很分明:因为不反对天子,所以大军一到,便受招安,替国家打别的强盗—不‘替天行道,的强盗去了。终于是奴才。”
宋江的问题不是他“是否英雄”,“是否有勇有谋”,而是他搞错了一个根本问题:就是“为谁而战?”,应该是为老百姓而战,而不是为皇帝而战。搞错了“替天行道”的这个天是谁这个基本道理,天应该是民意而不是封建统治阶级。他压根没搞明白“爱国”和“爱朝廷”是两码事。
毛主席说过:“《水浒》这部书,好就好在投降。做反面教材,使人民都知道投降派。《水浒》只反贪官,不反皇帝。”
导演一厢情愿的歪曲原著讴歌忠义,要替宋江平反不惜添油加醋,是导演想相谁献媚呢?还是想为为谁维稳?我觉得实在是该记导演一大功劳呀!!
……